Today’s post kicks off the first of three discussing the use of HP Networking command line to monitor, prevent and troubleshoot issues at the port level. HP feature toolbox has a lot to offer in handling various port issues including: STP, rate-limiting, loop protection, port-security etc. One of the more common port issues, and one we’ll continually revisit, is network loops. While we will be covering loops in these posts we won’t be talking about how to prevent loops using Spanning Tree Protocol as it entails a post onto itself.
Monitoring
An ounce of prevention is worth a pound of cure
As Benjamin Franklin said, “An ounce of prevention is worth a pound of cure.” and as such monitoring is key to prevention. You can’t prevent what you can’t see. One of the quintessential network support forum posts goes something like this: “I’m having an issue. I captured packets and I’m seeing this.” The first knowledgeable response often follows along the lines of “Well is this normal?” Outside of an obvious issue where 90% of your traffic is ARP, if you don’t know how your network typically operates you’ll have a heck of a time finding the source of your problems. With this in mind, let’s start watching our network.
Syslog
The first thing we’ll want to do is enable some logging parameters and send all the events to our centralized logging server. You do have centralized logging don’t you? I won’t wax poetic on the benefits of keeping your logs centralized, but I’d encourage you to look into it if you haven’t already done so.
To send events to a syslog server we need to specify the ip address and tell the switch to use the syslog format.
logging 172.16.1.10 logging facility syslog
Additionally it’s also useful to set a snmp trap receiver should you like to use them.
snmp-server host 172.16.1.10 community "ohsosecret" trap-level all
Fault finder
The fault detection system does a great job in finding the common day-to-day issues you find on a network. By default HP Network devices have fault-finder enabled to warn you about any issues. Additionally it has the capability to take action when it sees problems which we’ll cover later.
Switch# sh fault-finder Fault Finder Fault ID Sensitivity Action ------------------- ----------- ---------------- bad-driver medium warn bad-transceiver medium warn bad-cable medium warn too-long-cable medium warn over-bandwidth medium warn broadcast-storm medium warn loss-of-link medium warn duplex-mismatch-HDx medium warn duplex-mismatch-FDx medium warn link-flap medium warn
Each fault ID matches with a possible cause instead of effect – which seems odd to me. For instance bad-driver indicates when the switch has seen too many small or large packets. One possible cause could be a bad NIC driver, but it could be hardware issue with the NIC. So why not just call the fault ID packet-size or alike? Regardless, here’s a brief description of each of the fault IDs.
- bad-driver – Too many packets shorter than 64 bytes or longer than 1518 bytes.
- bad-transceiver – Jabbering – Oversized packets with CRC errors
- bad-cable – CRC/alignment errors
- too-long-cable – Late collisions
- over-bandwidth – A large number of collision or dropped packets
- broadcast-storm – Large number of broadcasts packets
- duplex-mismatch-HDx – Duplex mismatch
- duplex-mismatch-FDx – Duplex mismatch
- link-flap – Port state flapping
- loss-of-link – Port offline
The sensitivity column tells you the threshold before the warning is thrown. A High sensitivity means that fewer packets will cause the warning state, while a Low sensitivity means more packets. Each fault ID has it’s own number of packets and time period associated with the sensitivity. Pulling two examples from the documentation:
Condition | High | Med | Low | Packets | Time ====================================================== over-bandwidth | 6 | 21 | 36 | 1/10,000 | 5min broadcast-storm | 2750 | 9200| 15.6k | 1 | 1sec
There’s nothing on the switch that will give you these numbers so you’ll have to refer to the documentation here.
In the event that a fault is found you’ll see messages shows up as FFI (Find Fix Inform) in logs:
W 01/01/90 00:06:02 00331 FFI: port 37-High collision or drop rate. See help. W 01/01/90 00:05:51 00332 FFI: port 2-Excessive Broadcasts. See help. W 01/01/90 00:05:51 00332 FFI: port 1-Excessive Broadcasts. See help.
Instrumentation Monitor
The next monitoring feature from HP is the instrumentation monitor. Like the fault finder above, it has a host of metrics that can be continually monitored. Keep in mind that the instrumentation monitor only processes each of the metrics once every 5 minutes, so don’t expect a notification the moment an issue occurs.
This one is not enabled by default, so our first step is to enable the monitor and send the events to our syslog.
instrumentation monitor log
With the instrument monitor enabled it’ll also configure the ten instrument parameters with default thresholds.
Switch# sh instrumentation monitor configuration PARAMETER LIMIT ------------------------- --------------- mac-address-count 1000 (med) ip-address-count 1000 (med) system-resource-usage 50 (med) system-delay 3 (med) mac-moves/min 100 (med) learn-discards/min 100 (med) pkts-to-closed-ports/min 10 (med) arp-requests/min 1000 (med) login-failures/min 10 (med) port-auth-failures/min 10 (med) SNMP trap generation for alerts: disabled Instrumentation monitoring log : enabled
Here’s a brief description of each of the metrics:
- mac-count – Number of learned mac addresses in the forwarding table
- ip-address-count – Number of learned destination IP addresses in the IP forward table
- system-resource-usage – Percent of system resources in use
- system-delay – CPU response time to events
- mac-moves – Average number of MAC address moves
- learn-discards – Number of MAC addresses learn events discarded by switch under heavy CPU usage
- pkts-to-closed-ports – Number of packets sent to closed switch TCP/UDP ports (not interfaces)
- arp-requests – Number of arp requests per minute
- login-failures – Failed CLI or SNMP authentication attempts
- port-auth-failures – Unsuccessful logging into the network
Looking through our logs for instances of our new inst-mon parameters we see the default settings don’t match with our environment.
W 08/27/13 11:50:16 00830 inst-mon: Limit for MAC addr count (1000) is exceeded
(1305)
The mac-address parameter has three predefined settings: Low 100, Medium 1000 and High 10,000. None of these represents the daily upper limit of our environment so we’ll define our own threshold.
Switch# instrumentation monitor mac-address-count 2000 Switch# sh instrumentation monitor configuration PARAMETER LIMIT ------------------------- --------------- mac-address-count 2000 ip-address-count 1000 (med) system-resource-usage 50 (med) system-delay 3 (med) mac-moves/min 100 (med) learn-discards/min 100 (med) pkts-to-closed-ports/min 10 (med) arp-requests/min 1000 (med) login-failures/min 10 (med) port-auth-failures/min 10 (med)
Additionally, we can also utilize the snmp trap receiver we setup earlier for these notifications
Switch# instrumentation monitor trap
The documentation does a great job of further explaining each as well as customizing the thresholds.
Loop Protection
HP’s loop protection has a simple enough implementation. It sends sends out loop protocol packets and if it receives them back, we have a loop. As with the fault finder above, the Loop Protection feature has the ability to simply monitor or to monitor and take action.
Here we’ll enable Loop Protection and use the no-disable parameter so that we’re monitoring and not taking action.
Switch# loop-protect 1-5 receiver-action no-disable Switch# loop-protect trap loop-detected
Now if we create a loop on our network we’ll see something like the following.
Switch# sh log -r
Keys: W=Warning I=Information
M=Major D=Debug E=Error
---- Reverse event Log listing: Events Since Boot ----
I 01/16/90 16:44:46 00886 loop-protect: port 1 - loop detected.
I 01/16/90 16:44:43 00076 ports: port 2 is now on-line
I 01/16/90 16:44:43 00076 ports: port 1 is now on-line
[...]
Switch# sh loop-protect
Status and Counters - Loop Protection Information
Transmit Interval (sec) : 5
Port Disable Timer (sec) : Disabled
Loop Detected Trap : Enabled
Loop Loop Loop Time Since Rx Port
Port Protect Detected Count Last Loop Action Status
---- ------- -------- ------ ----------- ------------ --------
1 Yes Yes 4 0s no-disable Up
2 Yes Yes 3 4s no-disable Up
3 Yes No 0 no-disable Down
4 Yes No 0 no-disable Down
5 Yes No 0 no-disable Down
You’ll notice a few things: a loop has been detected. it has a count to show the number of loop-protect packets its received and the time since it last received a loop packet. Because we’re using the no-disable parameter both ports are still Up. At the moment we’re concerned with monitoring, so the loop will continue until we break it or the switch goes down.
The two other customizable parameters for this monitor are Port Disable Timer (sec), which we’ll cover in the next post and Transmit Interval (sec). Transmit Interval specifies the number of seconds between when loop protection packets are sent. Its worth noting that these packets are multicast to any HP switches, so if you enable loop protection on your edge switches that face other customers, this will add to their traffic however minute. HP’s loop protection packets look like the following:
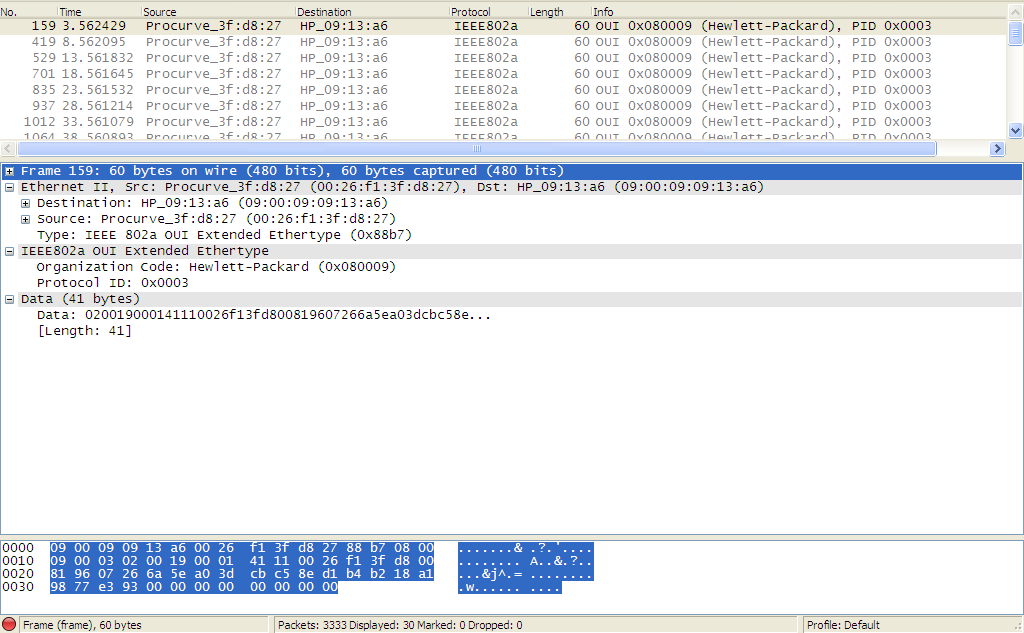
We can also enable traps with the following command.
Switch# loop-protect trap loop-detected
For more in-depth details on Loop Protection refer to the documentation.
This concludes the first post on port troubles with HP Networking. In this post we covered three monitoring features from HP: Fault Finder, Instrumentation Monitor and Loop Protection. With these three features we’ve covered a large range of the port issues you’ll encounter in your day-to-day operations. If you’re not using traps, then make sure you watch the logs. In the next HP Port Troubles post we’ll cover how to prevent these issues and we’ll revisit some of the monitors above and show how they can be used for prevention.
One thought on “HP Port Troubles Part 1: Monitoring”